robots.txtとは?書き方とSEO効果を解説【記述例あり】
更新日:2026年03月27日
Webサイトの運用において、robots.txt(ロボッツテキスト)は、意外と見落とされがちですが重要な設定の一つです。
なぜなら、robots.txtの設定によって検索エンジンのクローラー(巡回ロボット)の動きを制御するからです。つまり、記述を間違えるだけで、「検索結果からサイトが消えてしまう」というリスクもあるということ。
本記事ではrobots.txtとは何か、基本的な役割からSEO効果を高める正しい書き方、そして迷いがちなnoindexとの使い分けまで記述例や確認ツールも交えて詳しくご紹介します。
>>テクニカルな対策に役立つ「Google Search Console入門書」をダウンロードする
robots.txtとは?SEOにおける役割と重要性
robots.txtとは、「検索エンジンのクローラーに対して、サイト内のどのページを見てほしいか(あるいは見てほしくないか)を伝える指示書」のようなテキストファイルです。
Webサイトのサーバー上に設置することで、Googleなどの検索エンジンロボット(クローラー)がサイトに訪れた際に、最初にこのファイルを読み込み、「ここは入ってOK」「ここは立ち入り禁止」というルールを確認します。
検索エンジンのクローラーに「指示」を出すファイル
検索エンジンは、Web上のあらゆる情報を収集するために、クローラーと呼ばれるプログラムを巡回させています。robots.txtは、このクローラーに対して以下のような制御をおこなうために利用されます。
- クロール許可(Allow):特定のページやディレクトリの巡回を許可する
- クロール拒否(Disallow):特定のページやディレクトリの巡回を拒否する
例えば、会員限定のマイページや、開発中のテスト環境、システム管理画面など、検索エンジンに読み取られる必要のないページへのアクセスをブロックする際に非常に有効。
但し、robots.txtの指示をクローラーが必ず従うとは限らない点に注意が必要です。
robots.txtを作成して公開する4ステップ
robots.txtはGoogleの公式ドキュメントに記載されている以下の4ステップの通り、指定ルールでテキストファイルを作成してアップロードとテストを実施します。
robots.txt ファイルを作成して一般に公開し、正しく機能させるためには、次の 4 ステップを行います。
1.robots.txt という名前のテキスト ファイルを作成します。
2.robots.txt ファイルにルールを記載します。
3.サイトのルートに robots.txt ファイルをアップロードします。
4.robots.txt ファイルをテストします。
(出典:robots.txt の書き方、設定と送信 | Google のクロール インフラストラクチャ)
SEO効果に影響するクロールバジェットの最適化とは
robots.txtの適切な設定は、SEOにおいてクロールバジェットの最適化という効果が期待できす。
Googleのクローラーが1つのサイトを巡回するリソース(時間や回数)には限りがあり、これを「クロールバジェット」と呼びます。
もし、サイト内に価値の低いページや重複ページが大量にある場合、クローラーがそれらの無駄なページにリソースを割いてしまい、本当に評価してほしい重要な記事や商品ページへ巡回しないと機会損失。
robots.txtを使って不要なページへのクロールを拒否することで、限られたクローラーのリソースを重要なページに集中させ、新しいコンテンツのインデックス速度や評価の更新を早める効果が期待できます。
特に、ページ数が膨大な大規模サイトでは、このコントロールがSEO対策において重要です。
robots.txtとnoindexの違いと使い分け
robots.txtを理解する上で重要なのが、「robots.txtはインデックスを拒否するためのものではない」という点。
ここを混同すると、意図したインデックス制御と異なる状況になりかねません。
| 項目 |
robots.txt (Disallow) |
noindexタグ |
| 主な役割 |
クローラーの巡回(アクセス)を拒否する |
インデックスを拒否する |
| 検索結果への表示 |
表示される可能性がある |
確実に表示されなくなる |
| 使用シーン |
クロール負荷を下げたい時
画像やスクリプトを除外したい時 |
検索結果からページを消したい時 |
特に、検索結果から消したいページにrobots.txtでブロックをかけるという誤った使い方はよくあるミス。
もしrobots.txtでクロールを拒否してしまうと、クローラーはそのページの中身を見ることができません。そのため、ページ内に「noindex(インデックスしないで)」というタグが書かれていても、クローラーはその指示を読み取ることができません。
検索結果に出したくない場合はnoindexタグを、クローラーに来てほしくない場合はrobots.txtを使用する、この使い分けを理解しておきましょう。
コピペで使える!robots.txtの正しい書き方と記述例
ここからは実務ですぐに使えるrobots.txtの書き方を解説します。
基本的にはテキストエディタ(メモ帳など)で作成し、ファイル名を「robots.txt」として保存するだけです。
基本構文:User-agent・Disallow・Allow・Sitemap
robots.txtは、主に以下の4つの記述を組み合わせて構成されます。
| 項目 |
詳細 |
User-agent
(ユーザーエージェント) |
どのクローラーに対する指示かを指定します。すべてのクローラーを対象にする場合は「*(アスタリスク)」を使います。 |
Disallow
(ディスアロウ) |
クロールを拒否するディレクトリやページを指定します。 |
Allow
(アロウ) |
Disallowで拒否した階層の中で、例外的にクロールを許可するページを指定します。(Googlebotなどはデフォルトで全許可なので、Disallowの例外指定として使います) |
Sitemap
(サイトマップ) |
XMLサイトマップ(sitemap.xml)の場所を記述し、クローラーに伝えます。 |
記述例:一般的な設定
全てのクローラーに対して、管理画面(/admin/)へのアクセスを拒否し、サイトマップの場所を伝える場合の記述です。
User-agent: *
Disallow: /admin/
Sitemap: https://www.example.com/sitemap.xml
※上記は作成したXMLサイトマップ「sitemap.xml」がドメイン直下に設置されている場合の例
指定のクローラー(GPTBotなど)をブロックする書き方
現在は検索エンジンのクローラーだけでなく、ChatGPTなどの生成AIが学習データ収集のために巡回するクローラーも存在します。自社のコンテンツをAIの学習に使われたくない場合は、robots.txtで明示的に拒否設定をおこなう企業も増えています。
例えば、OpenAI社のクローラー「GPTBot」をブロックする場合の記述は以下の通りです。
User-agent: GPTBot
Disallow: /
このように、特定のUser-agentを指定して個別のルールを設定することが可能です。
WordPressサイトで推奨される記述パターン
WordPressを使用している場合、管理画面や重要なコアファイルへのアクセスはセキュリティ的にもSEO的にもブロックしておくのが一般的です。一方で、Googleがページを正しくレンダリングするために必要なCSSやJavaScriptファイルなどはブロックしてはいけません。
一般的なWordPressサイトでの記述は以下のようになります。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.example.com/sitemap.xml
※/wp-admin/は管理画面ですが、admin-ajax.phpはフロントエンドの動作に必要な場合があるため、Allowで許可するケースが一般的です。
>>テクニカルな対策に役立つ「Google Search Console入門書」をダウンロードする
robots.txtの設定場所とアップロード方法
記述ファイルが完成したら、それをサーバー上の正しい場所にアップロードします。この場所を間違えると、クローラーはファイルを認識してくれません。
ルートディレクトリへの設置が必須条件
robots.txtは、必ずWebサイトのルートディレクトリに設置する必要があります。
ルートディレクトリとはドメイン直下の場所のこと。
- ◯ 正しい設置URL: https://www.example.com/robots.txt
- × 間違った設置URL: https://www.example.com/blog/robots.txt
サブディレクトリ(/blog/など)の中に置いても効果はありませんので、必ず一番上の階層にアップロードしましょう。
FTPソフトやレンタルサーバー管理画面での設定手順
ファイルのアップロードには、一般的に以下のいずれかの方法を使用します。
- FTPソフトを使用する
- レンタルサーバーのファイルマネージャーを使用する
- WordPressプラグインを使用する
FTPソフトを使用する場合は、FileZillaなどのFTPソフトを使ってサーバーに接続し、作成したrobots.txtファイルをルートフォルダ(public_htmlやwwwなど)にアップロードします。
レンタルサーバーのファイルマネージャーを使用する場合は、XserverやConoHa WINGなどの管理画面に用意されている、ブラウザ上でファイルを操作できる「ファイルマネージャー」機能を使用します。ここから直接アップロードや作成が可能。
また、一部のWordPressプラグインでは、仮想的なrobots.txtを生成・編集できる機能がついている場合があります。実ファイルをアップロードしなくても管理画面から編集できるため、初心者の方には便利ですね。
設定ミスを防ぐ!robots.txtの確認・テスト方法
robots.txtの設定ミスは、サイト全体の検索流入をゼロにしてしまう危険性があります。設定後は必ず正しく動作しているかを確認しましょう。
ブラウザで直接アクセスして確認する
最も簡単な確認方法は、ブラウザのアドレスバーに「自社サイトのURL + /robots.txt」を入力してアクセスする方法です。
例:https://www.example.com/robots.txt
ここで、作成した記述内容がテキストとしてそのまま表示されれば、ファイルは正しく設置されています。
万が一404エラー(ページが見つかりません)が出る場合は、設置場所が間違っているか、ファイル名が間違っている可能性があるため、正しいファイル名を適切にアップロードできているか確認してみましょう。
Google Search Consoleの「robots.txtレポート」活用法
Google Search Console(サーチコンソール)を使用している場合、以前は「robots.txtテスター」というツールがありましたが、現在は「設定」→「robots.txt」レポートから、Googleが認識しているrobots.txtの内容とステータスを確認できます。
ここで「取得済み」となっていればGoogleは正常にファイルを読み込んでいます。
もし記述にエラーがある場合は「問題の件数」に警告が表示されるためチェックすることをおすすめします。
robots.txtレポートのエラー表示例
下記図は、弊社クリエルのWebサイトで再現したrobots.txtレポートのエラー表示例です。
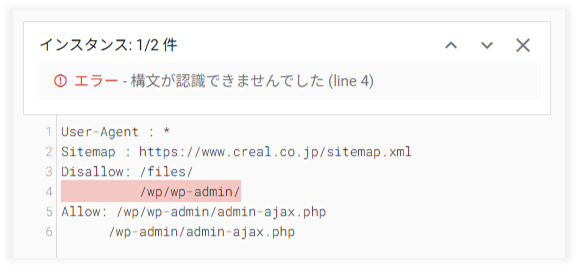
この図では4行目に記述エラーが出ていることがわかります。
正しくは「Disallow:」から記述が必要なのですが、3行目の記述に続けてしまっている状態。この画面でエラーの有無や該当箇所を確認できるため、エラー発生時は正しい記述へ修正しましょう。
また、「インスタンス: 1/2件」とあるように、もう一箇所エラーがあります。この場合は画面右上「∨」をクリックすると2件目のエラーへ表示が切り替わりますので、同様に修正箇所を確認しましょう。(上図の例では6行目に同様のエラーが発生している状態です。)
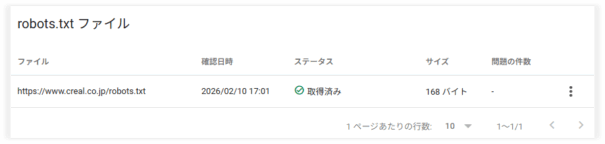
robots.txtレポートが正常な場合の表示例
robots.txtレポートでエラーが検知されていない場合は、「設定」→「robots.txt」レポートの画面で下図のようにステータスが取得済みで、問題の件数列にエラー表示がない状態となります。
また、特定のページがブロックされているかどうかをテストしたい場合は、Search Console内の「URL検査ツール」を使用し、対象URLを検査することで「クロールが許可されているか」を診断できます。
robots.txtとは別モノの「llms.txt」とは?
最近、SEO業界をはじめAI検索(ChatGPTやAI Overviewsなど)に注目している方たちの間で「llms.txt」という新しいファイル形式が注目されています。
robots.txtがクローラーに対して「アクセス許可/拒否」を伝えるのに対し、llms.txtとは、ChatGPTなどの生成AIに対して「AIが読みやすい形式のファイルはここにあります」と案内板を出すためのファイル。
AI検索が普及するにつれ、AIに正しく自社の情報を引用してもらうための施策(LLMO)として、将来的にはrobots.txtと同様にスタンダードになる可能性があります。
こちらもrobots.txtと同様に適切な使い分けが重要になるかもしれませんね。
robots.txtに関するよくある質問
ここからはrobots.txtに関するよくある質問と回答をご紹介します。
Q.robots.txtは必ず設定しなければなりませんか?
A.いいえ、必須ではありません。小規模なサイトで、全てのページを検索結果に表示させたい場合は、robots.txtがなくても問題なくインデックスされます。ただし、不要なページがある場合や、サイトマップの場所を伝えたい場合は設定を推奨します。
Q.設定を変更した後、どのくらいで反映されますか?
A.通常、Googleのクローラーは24時間以内にキャッシュされたrobots.txtを更新しますが、即時反映されるわけではありません。急いで反映させたい場合は、Search Consoleからrobots.txtの再クロールリクエストを申請することができます。
Q.特定の画像だけ検索に出ないようにできますか?
A.はい、可能です。Disallowの指定で、特定の画像ファイル(例:.jpg)や画像フォルダを指定することで、Google画像検索などへの露出を防ぐことができます。
robots.txt活用法のまとめ
robots.txtは、検索エンジンのクローラーを適切に制御する上で有効なファイルです。
「クロールバジェットの最適化」や「不要なアクセスのブロック」といったメリットがある一方で、記述ミスによるインデックス消失のリスクも伴いますので、正しい知識を持って設定しましょう。
まずは現状の設定を確認し、意図しないブロックがかかっていないか、あるいは重要なページが放置されていないか、チェックすることから始めてみてはいかがでしょうか。
もし、この機会にSearch Consoleの他の項目もチェックする場合は、「Google Search Console入門書」もご活用くださいね。
Web担当者がSEOで失敗しないための
サーチコンソール活用法

SEOで失敗して後悔しないためには”守りのSEO”が重要です。
そこで活用したいのがGoogle Search Console。
無料でダウンロードいただける本資料ではアカウント開設から活用法まで解説し、BIGキーワードをはじめ、様々なWebマーケティングジャンルで上位表示させてきた弊社でもフル活用しているGoogle Search Consoleの機能をご紹介しています。
▼本資料に掲載されている内容の一例は・・・
・サーチコンソールの登録方法
・最初に活用するべき機能とは?
・ページが検索結果に表示されない時の対処法
・放置厳禁!Googleからのメッセージと考え方とは?
・様々なメニューに実装されている機能
まだ利用されていない方も、十分に活用できていない方も、ぜひSEO対策にご活用ください。